







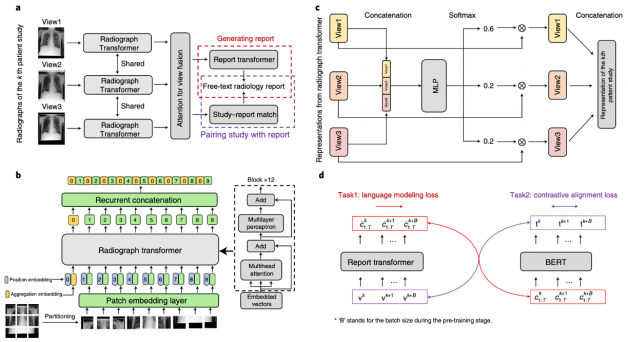
港大工程學院的研究團隊開發出一種嶄新人工智能演算方法REFERS(Reviewing Free-text Reports for Supervision),能夠從數十萬份X射線影像報告中自動獲取監督信號來訓練預測模型,大幅減省人力成本達90%,其預測的準確度更超越用全由人手標註的數據訓練的人工智能醫學圖像診斷模型。
REFERS利用人工智能直接從文本報告中學習X射線特徵表達。與嚴重依賴人手標註的傳統方法相比,REFERS能夠自動從文本報告中的每個詞獲取監督信號,用以訓練人工智能神經網絡精確解讀X射線影像。
研究團隊利用公開數據庫37萬份X射線影像和文本報告作為訓練模型的基礎,當中包含14種胸肺相關疾病包括肺不張、心臟肥大、胸腔積液、肺炎和氣胸等醫療診斷數據。在訓練預測模型的過程中,團隊僅使用100張X射線影像便已建立了一個初步令人滿意的X射線影像識別模型,其預測準確度達83%。當使用的影像增加到1000張,模型更展示出驚人的性能,預測準確度達88.2%,超越了用放射科醫生標註的10000張X射線影像進行訓練的模型(準確度87.6%)。而當用作訓練的影像增加到10000張,模型的準確度更達到90.1%。而一般來説,預測模型的準確度達85%以上,已可作實際臨床診斷應用。
領導研究團隊的港大工程學院計算機科學系教授俞益洲表示,由人工智能推動的醫學圖像診斷極具潛力,可以減輕醫學專家的工作量及提高診斷效率和準確性,其中包括節省診斷時間及檢測一些不易察覺的異常跡象。有關研究成果已於《自然-機器智能》期刊發表。
相關閱讀:
稿件由上傳 · 文責自負 · 不代表本網立場




